Seedance 2.0: The Leading AI Video Model
Recently, many have quickly shifted their opinions to Seedance 2.0 as the best AI video model globally. Two weeks ago, Irish filmmaker Lueri Robinson, nominated for an Oscar for Best Animated Short, used just two lines of prompts to generate the viral AI video “Tom Cruise vs. Brad Pitt”, which has sent shockwaves through Hollywood.
Deadpool and Wolverine screenwriter Rhett Reese expressed his concerns on social media after watching the video:
I hate to say it, but we (filmmakers) might really be doomed.
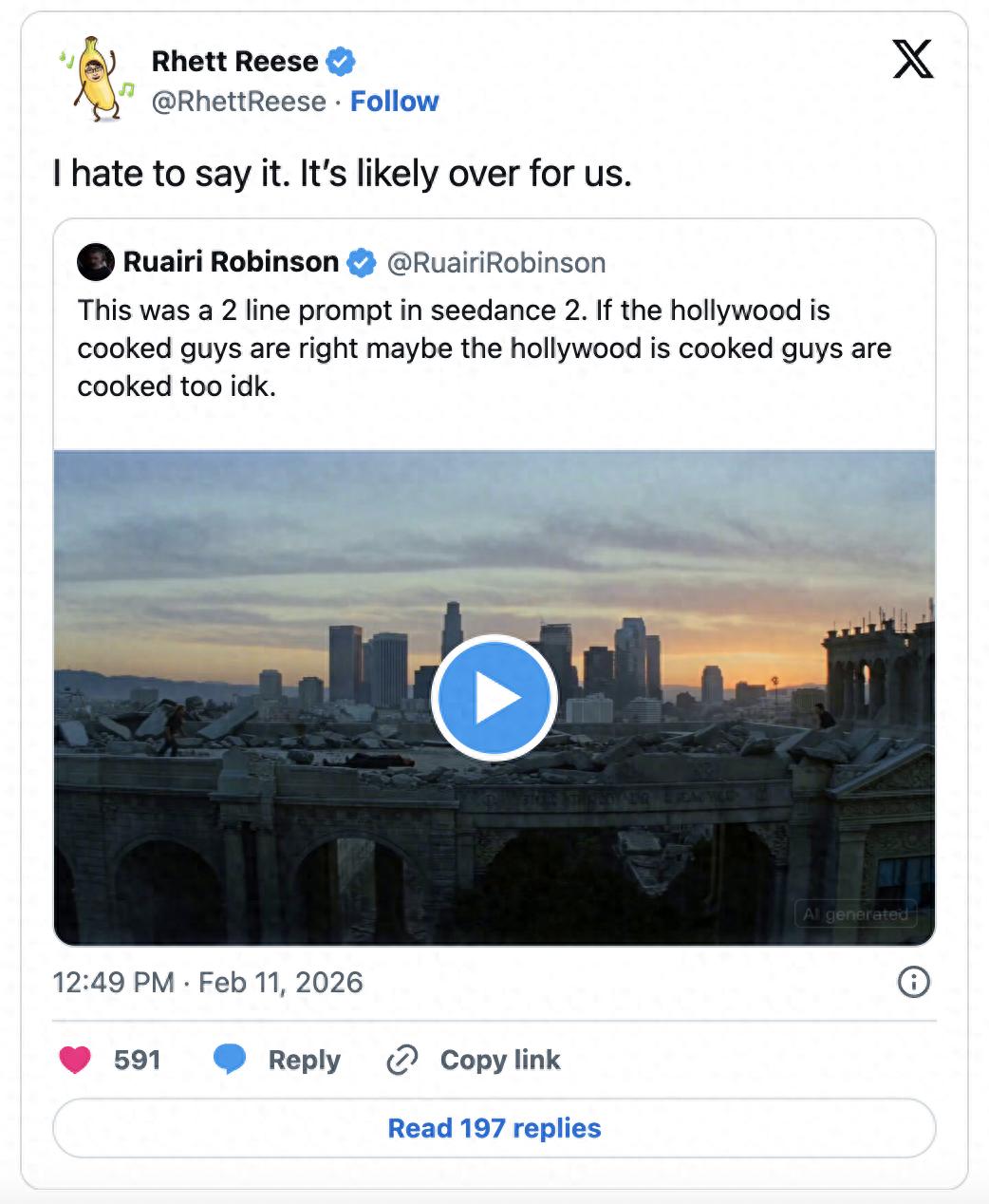
Seedance 2.0’s AI video has Hollywood’s top screenwriters fearing for their future.
Due to its powerful capabilities, Seedance 2.0 has sparked a wave of AI creativity on the internet, leading to a surge of movie-quality AI videos. As viewers marvel at the rapid evolution of AI technology, the feedback from users of Seedance 2.0 is equally noteworthy.
If the emergence of Sora showcased AI’s magic of “creating something from nothing,” Seedance 2.0 shifts the focus back to “how to generate exactly what I want.”
Seedance 2.0 employs a robust multi-dimensional reference system to transform vague ideas into precise instructions executable by AI. It has made remarkable advancements in character consistency, native audio-visual synchronization, and automatic camera switching.
While discussing the advantages and features of Seedance 2.0, users also inevitably mention its shortcomings, which may indicate future directions for AI video model development. The evolution of AI is far from over, and with each groundbreaking product like Seedance 2.0, the urgency to learn and adapt increases.
01 Goodbye Random Generation: Seedance 2.0’s Clear Control Advantages
Seedance 2.0’s core competitiveness lies not in isolated technological breakthroughs but in a director-intent-centered collaborative architecture. Creators finally have the opportunity to transition from a passive role of “hoping AI understands” to that of a director at the control panel.
Specifically, Seedance 2.0 excels with its unified multi-modal audio-video generation architecture. Unlike traditional models that follow a single “text-to-video” path, Seedance 2.0 can simultaneously understand and integrate text, images, videos, and audio inputs. This means you can describe a story in words, define characters and styles with images, specify camera movements with videos, and drive rhythm and lip-sync with audio.
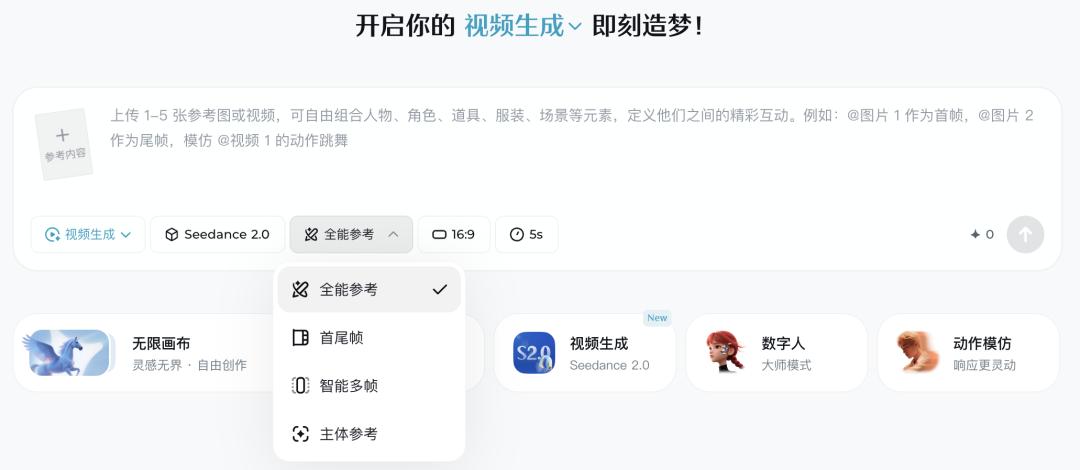
Seedance 2.0 can simultaneously understand and integrate inputs from text, images, videos, and audio.
The core of this architecture is the “director mode,” which transforms vague ideas into precise, executable instructions for AI through a powerful multi-dimensional reference system.
For example, Seedance 2.0 allows users to upload up to nine images, three videos, and three audio clips to build a rich “material library.”
Even more impressively, it introduces a reference system similar to the “@” symbol in programming. By using tags like @Image1 and @Video1 in prompts, creators can precisely bind instructions to specific materials. For instance, saying, “Make the character in @Image1 dance the dance in @Video1” is far more efficient and unambiguous than lengthy natural language descriptions.
Moreover, creators can adjust the “influence weight” of each reference material. For example, you can increase the weight of character images to ensure high facial fidelity while lowering the weight of motion reference videos, allowing AI to follow general movements while creatively interpreting them.

Seedance 2.0 leads the industry in instruction adherence, motion quality, visual aesthetics, and audio performance.
Stable, synchronized, and intelligent—under Seedance 2.0’s powerful multi-modal audio-video generation architecture, several key technologies have broken through, addressing core pain points in AI video creation.
- Seamless camera cuts with consistent character appearance and attire.
In the past, models often faced issues where characters would “change faces” or alter clothing details after camera switches. Seedance 2.0 allows users to upload multi-angle reference images of characters (e.g., front, side, three-quarters), constructing a more stable 3D geometric representation internally. This ensures that core facial features and clothing details remain consistent during dynamic processes like turning or lighting changes, providing solid technical support for generating multi-camera sequences.
- Precise audio-visual matching, even capable of voice reconstruction from a photo.
Audio-visual synchronization has been a persistent issue in AI video. Seedance 2.0 utilizes its underlying Seed 2.0 model, achieving precise synchronization of native video and audio (including dialogue, sound effects, and ambient sounds) in the same generation process through a structure known as the “dual-branch diffusion transformer.”
Remarkably, the model can even reconstruct a voice that closely mimics a person’s tone and mannerisms based solely on a static facial photo. Although this feature has been temporarily suspended due to potential ethical and legal risks, it showcases the model’s impressive depth in understanding the relationship between biological features and sound.
Additionally, audio waveforms can directly drive character facial animations, achieving highly realistic lip-syncing, making digital character performances no longer feel disjointed.
- Automatic camera switching allows even novices to create cinematic experiences.
Seedance 2.0 includes a “narrative planner” that thinks like a director. When given a story outline, it can automatically break it down into professional shot sequences (e.g., long shot - medium shot - close-up) while maintaining character and style consistency during transitions. Even users unfamiliar with storyboarding can generate cinematic montage segments, significantly lowering the barriers to video storytelling.
02 Technical Bottlenecks Beneath the Gloss
Despite Seedance 2.0’s significant strides in controllability, it still has notable gaps from a technical perspective, falling short of being a perfect “world simulator.” Compared to competitors like Sora 2 and Google Veo 3.1, Seedance 2.0 is not leading in all aspects.
- Complex physical effects still lack realism.
Current AI video models remain at the level of “pattern matching” rather than “first principles” in understanding the physical world. This leads to exposure of shortcomings when handling complex or uncommon physical interactions. For instance, while Seedance 2.0 can generate simple splash effects adequately, its simulations of more complex liquid flows, fabric wrinkles during high-speed movements, and fine hair movements still appear stiff and lack realism.
When dealing with multiple object collisions, stacking, or intricate operations, Seedance 2.0 occasionally exhibits “AI quirks” like clipping, floating, or unnatural acceleration, indicating a substantial need for improvement in its understanding of spatial relationships and mechanical transmission.
- Long video creation faces detail drift and coherence issues.
Although Seedance 2.0 maintains good coherence in single-generation clips lasting several seconds, problems arise when extending the time scale. All current video models face the challenge of “memory decay.” In a narrative video lasting several minutes, ensuring consistent motivations for character actions and maintaining continuity of object states in scenes demands high long-term memory capabilities from the model. Currently, such videos still require manual editing and segmented generation to ensure quality.
Additionally, in some user-generated videos, subtle “texture drift” or “flickering” phenomena may appear in the latter half of the video, especially on intricate patterns, text, or background elements.


In the AI short film “Apex,” the angles of vehicle collisions and the way windows shatter clearly do not align, and the text on the vehicle appears to be garbled.
- Realistic content generation lacks the authenticity of competitors.
Compared to Sora 2 and Veo 3.1, Seedance 2.0 exhibits differentiated advantages across multiple dimensions while also revealing some disadvantages. Sora and Veo aim to “simulate a real world,” while Seedance 2.0 focuses on “constructing a controllable set.” For short content that requires rapid output and high realism, Veo 3.1’s native audio-visual synchronization may be a better choice. However, for professional creators needing fine control over character performances, camera language, and artistic style, Seedance 2.0’s director mode is undoubtedly more appealing.
When generating purely realistic content without references, the realism and detail of characters generated by Seedance 2.0 sometimes fall short compared to its two competitors. This may stem from differing design philosophies in model architecture and training data emphasis.
03 Is the “World Model” the Ultimate Evolution Direction?
Analyzing the advantages and shortcomings exhibited by Seedance 2.0 allows us to outline the next stage of evolution for AI video models. Future competition may no longer focus solely on generating clearer, more realistic images but rather on constructing a “world model” that understands physics and narrative.
In the AI field, the concept of a “world model” is frequently mentioned.
In simple terms, world model = enabling AI to “simulate the entire world” in its mind. It is not merely about “seeing images and generating videos” but teaching AI about objects in the world, how they interact, the rules of physics, and how events unfold, thereby constructing a virtual, inferable world internally.
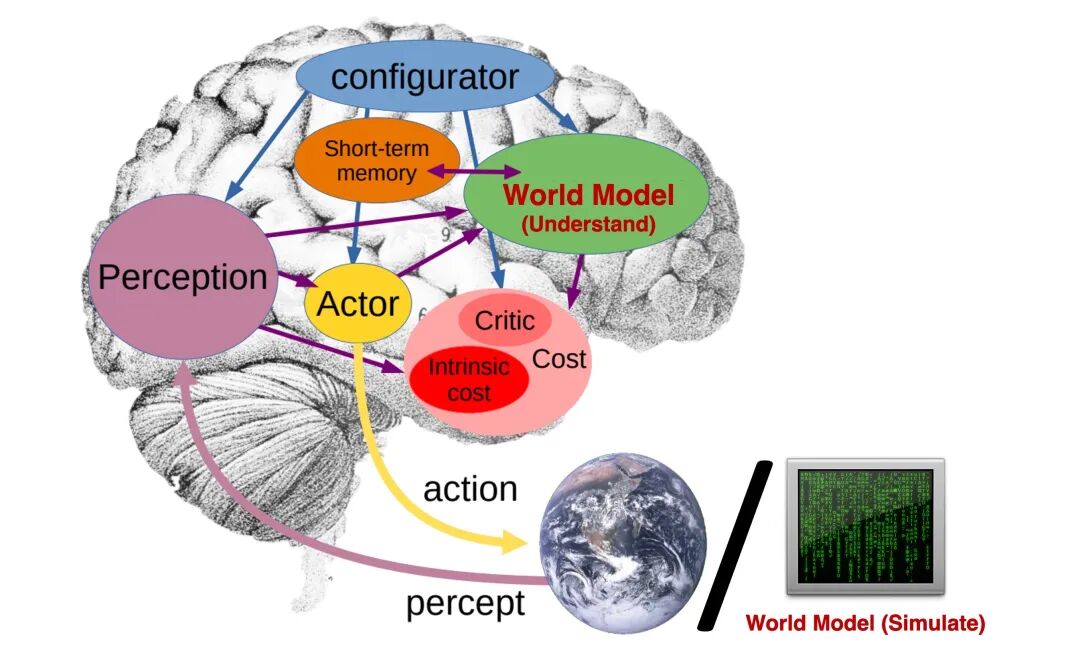
The “world model” may be the ultimate evolution direction for AI video models.
The core breakthrough for the next generation of video models will be the depth and breadth of their “world models.” This requires models to possess stronger causal reasoning abilities, achieving global consistency based on unified physical logic.
For example, when a prompt describes “a gust of wind blowing through,” the model should not only generate an image of swaying leaves but also infer how this wind affects distant flags, people’s hair, and ripples on the water’s surface. This global consistency based on unified physical logic will be key to achieving true immersion in AI video.
Like a game engine, first construct a virtual world, then “run” an event within that world and “film” it with a virtual camera. In this paradigm, all physical interactions, lighting changes, and character behaviors will be self-consistent and logical.
Moreover, with the proliferation of spatial computing devices like Apple Vision Pro, future AI video models may no longer be limited to a flat “frame” but could represent a complete, immersive 3D scene for users to enter and explore.

As spatial computing devices become more prevalent, future AI video models are likely to explore 3D scenes.
Creators may be able to directly position virtual cameras in 3D space and plan their movement trajectories, while AI handles the real-time rendering of video streams from those perspectives. Seedance 2.0’s director mode can be seen as an early prototype of this direction.
In summary, the emergence of Seedance 2.0 is a significant industry milestone— in the second half of AI video, mere generative capability is no longer the sole trump card; controllability and predictability will become the core standards for assessing whether a model possesses industrial potential. For creators, technology is shifting from a challenging “creative partner” to a truly user-friendly “creative tool,” allowing great ideas to flourish even more.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.